

jyamethyst21 님의 블로그
머신러닝 & 딥러닝 본문
이상치 탐지
- 데이터에서 일반적인 패턴과 크게 벗어나는 관측값을 식별하는 과정
- 데이터 분포와 동떨어져 있거나, 예상 범위를 벗어난 데이터 포인트를 나타냄
- 다른 데이터와 비교했을 때 비정상적이고, 통계적으로 드문 데이터 포인트
Isolation Forest
- Isolation Forest는 이상치 탐지를 위해 설계된 비지도학습 알고리즘
- 이상치는 일반적인 데이터보다 나누기 쉽다는 특징에 기반하여, 데이터를 반복적으로 나누는 방식
- 무작위 샘플링 -> 분리 깊이 계산 -> 여러 트리 구축 -> 이상치 점수 산출
- 고차원 데이터에서 효율이 떨어진다는 단점이 있지만, 데이터 크기와 관계없이 선형 시간복잡도가 O(n)
import numpy as np
import pandas as pd
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
np.random.seed(42)
normal_traffic = np.random.normal(loc=50, scale=10, size=(100,2))
ano_traffic = np.random.uniform(low=100, high=150, size=(10,2))
traffic_data = np.vstack((normal_traffic, ano_traffic))
traffic_df = pd.DataFrame(traffic_data, columns=['Request Time', 'Response Time'])
model = IsolationForest(n_estimators=100, contamination=0.105, random_state=42)
traffic_df['Anomaly_Score'] = model.fit_predict(traffic_df)
plt.scatter(traffic_df['Request Time'], traffic_df['Response Time'], c=traffic_df['Anomaly_Score'].map({1: 'blue', -1: 'red'}))fit_predict 이후 -1과 1로 분류가 되고 이를 통해 이상치 확인 가능
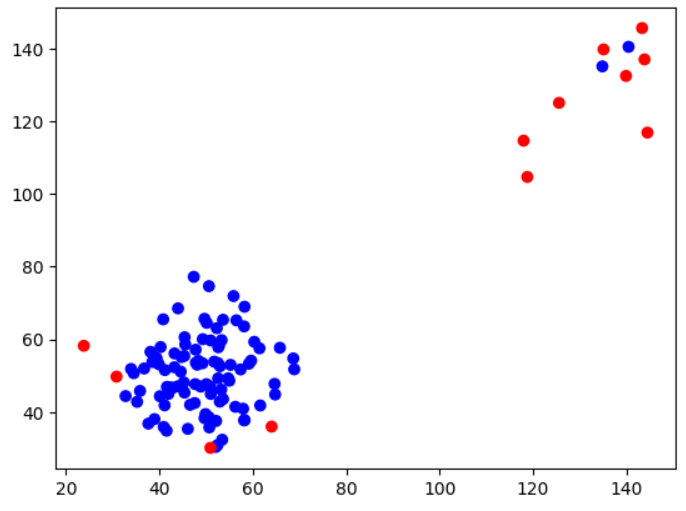
DBSCAN
- 밀도 기반 클러스터링 알고리즘
- 데이터를 밀도가 높은 영역과 밀도가 낮은 영역으로 나눔
- 데이터의 밀도가 충분히 높은 영역을 클러스터로 간주, 밀도가 낮은 데이터 포인트는 이상치로 분류
- 주요 개념
• Epsilon (ε) : 두 데이터 포인트가 같은 클러스터에 속하기 위해 허용되는 최대 거리
• MinPts : 클러스터가 형성되기 위해 필요한 최소 데이터 포인트 수
• Core Points : ε 반경 안에 MinPts 이상의 데이터가 포함된 포인트
• Border Points : ε 반경 내에 Core Point에 포함되지만 MinPts 조건을 만족하지 않는 포인트
• Noise (이상치) : Core Point나 Border Point에 속하지 않는 포인트
- 작동 원리
• 각 데이터 포인트에서 ε 반경 내 데이터 밀도를 계산
• 밀도가 높은 데이터 포인트(Core Point)를 중심으로 클러스터 형성
• 밀도가 낮은 포인트는 Noise(이상치)로 간주
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=15, min_samples=5)
traffic_df['Cluster'] = dbscan.fit_predict(traffic_df)
traffic_df['Anomaly'] = traffic_df['Cluster'].apply(lambda x: 'Anomaly' if x == -1 else 'Normal')
result_data = traffic_df[ traffic_df['Anomaly'] == 'Anomaly' ]
min_request_count = result_data['Request Time'].min()
max_request_count = result_data['Request Time'].max()
min_res_time = result_data['Response Time'].min()
max_res_time = result_data['Response Time'].max()
print(min_request_count)
print(max_request_count)
print(min_res_time)
print(max_res_time)
# 결과
106.70076142253204
145.20793472468742
100.7272332833941
120.17414331061985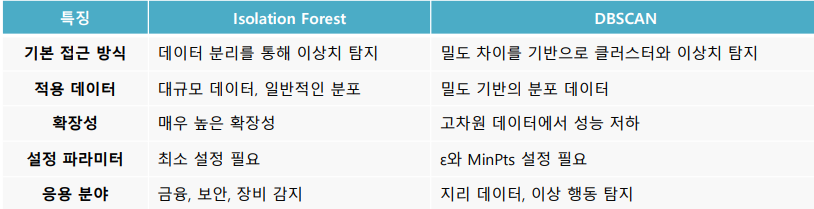
딥러닝
- 정의: 인공 신경망을 기반으로 한 머신러닝의 하위 분야로, 데이터를 바탕으로 복잡한 패턴을 학습하고 문제를 해결하는 것
- 계층적인 데이터 학습(여러층으로 구성된 신경망 사용)
- 여러층을 통과시키며 점점 더 높은 수준의 정보를 학습
- 단순한 특징 -> 복잡한 특징을 단계적으로 뽑아냄
- 머신러닝과 딥러닝의 차이
• 머신러닝: 데이터를 학습하기 전 사람이 주요 특징을 선정하고 이를 모델에 제공
-> 적은 양의 데이터로도 학습이 가능함
• 딥러닝: 자동 특징 학습이 가능
-> 매우 큰 데이터셋이 필요하고 비용이 높음
인공 신경망(ANN)
- 정의: 컴퓨터가 사람의 뇌를 본떠서 만든 알고리즘(사람 뇌의 뉴런 연결 방식을 흉내냄)
- 뉴런은 신경세포체(뉴런 중심 부분, 세포의 생명 유지와 대사 활동 담당), 가지돌기(다른 뉴런으로부터 신호를 받아들임), 축삭돌기(전기 신호를 먼 거리까지 전달)로 구성
- 퍼셉트론: 인공 신경망의 가장 기본적인 구성 요소(여러 입력을 받아 하나의 출력을 생성하는 단순한 모델)
• 입력: 여러 개의 입력을 받아들임(예를 들어 x1,x2...)
• 가중치: 각 입력에는 가중치라는 숫자가 곱해짐(예를 들어 w1,w2..)
• 편향: 계산에 더해지는 추가값(퍼셉트론이 더 유연하게 작동하도록 함)
• 합산기: 각 입력에 가중치를 곱한 후 모두 더하고 편향 값을 추가
• 활성화 함수: 합산된 값 s가 특정 임계값을 넘는지 확인(뉴런이 계산한 값이 그대로 다음으로 갈지, 얼마나 강하게 반응할지 결정)
• 출력: 최종적으로 1 또는 1의 값을 출력
• 학습 과정
1. 초기화 - 가중치와 편향을 임의의 값으로 설정
2. 예측 및 오차 계산 - 입력 데이터를 통해 예측 값을 계산하고, 실제 값과의 차이(오차)를 구함
3. 가중치 및 편향 업데이트 - 오차를 기반으로 가중치와 편향을 조정하여 모델이 점차 정확한 예측을 할 수 있도록 함
4. 반복 - 오차가 최소화될 때까지 또는 정해진 횟수만큼 위 과정을 반복
• 한계: 간단한 선형 분리 문제는 잘 해결하나 XOR 문제처럼 복잡한 문제는 해결하지 못함
- 신경망은 여러 층으로 구성되면 각각의 층은 뉴런의 집합
• 입력층: 데이터를 입력 받는 층으로 입력 데이터의 각 특징은 하나의 뉴런에 대응됨
• 은닉층: 입력 데이터를 처리하고 학습하는 층, 이전 층의 모든 뉴런과 연결되면 이를 완전 연결이라고 함, 은닉층의 개수와 뉴런 수는 문제의 복잡도에 따라 결정됨, 다층 구조의 은닉층을 가진 신경망을 심층 신경망(DNN)이라고 함
• 출력층: 최종 결과를 출력하는 층(최종 결과를 제공하는 층, 문제 유형에 따라 뉴런 수와 활성화 함수가 달라짐)
- 대표적인 활성화 함수
• ReLU: 0 이하는 0으로 꺼버리고, 양수는 그대로 통과
• Sigmoid: 결과를 0~1 사이로 눌러서 확률처럼 만들 때 사용
• Tanh: 입력값을 -1~1 사이로 압축하는 비선형 함수
• Softmax: 여러 클래스 중 각 클래스 확률을 만들 때 사용
- 신경망의 동작 원리
• 순전파: 데이터를 입력층에서 시작해 은닉층을 거쳐 출력층까지 전달하며 계산 수행
• 손실 함수: 츨력층에서 예측값과 실제값의 차이를 계산하는 함수(MSE, Cross-Entropy Loss)
• 역전파: 학습 과정에서 손실을 최소화하기 위해 가중치와 편향 값을 조정하는 과정(경사하강법 사용)
- 딥러닝 모델의 기본 구성
• 옵티마이저: 손실을 줄이기 위해 가중치를 어떻게 고칠지 정하는 수정 방법(SGD, Adam)
• 층 수와 뉴런 수는 모델의 복잡도에 영향을 미침(많은 층일수록 더 복잡한 패턴 학습 가능(과적합 위험 존재), 뉴런 수가 적으면 학습이 불충분할 수 있음)
Tensorflow, Keras를 활용한 간단한 신경망 모델 구성 예제
from tensorflow.keras.models import Sequential # 순차적 모델을 생성하기 위한 모듈
from tensorflow.keras.layers import Dense # 밀집층(fully connected layer)을 추가하기 위한 모듈
from sklearn.model_selection import train_test_split # 데이터를 학습/테스트 세트로 나누기 위한 모듈
from sklearn.datasets import make_classification # 예제 데이터셋 생성 모듈
X, y = make_classification(
n_samples=1000, # 데이터 샘플 수
n_features=20, # 특징(특성) 수
n_classes=2, # 클래스 수 (이진 분류)
random_state=42 # 랜덤 시드 고정 (결과 재현 가능성 보장)
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Sequential()은 모델을 레이어 순서대로 구성할 수 있도록 해줌
model = Sequential([
Dense(16, activation='relu', input_shape=(X_train.shape[1],)), # 첫 번째 은닉층
Dense(8, activation='relu'), # 두 번째 은닉층
Dense(1, activation='sigmoid') # 출력층 (이진 분류에서 사용)
])
# `input_shape`는 입력 데이터의 차원을 지정
# `activation`은 각 층에서 사용할 활성화 함수
# - relu: 0보다 큰 값은 그대로 두고, 작은 값은 0으로 설정 (비선형성 제공)
# - sigmoid: 출력값을 0과 1 사이로 제한 (이진 분류에서 확률 계산에 유용)
# 모델 학습 전에 학습 방법(optimizer), 손실 함수(loss), 평가 지표(metrics)를 정의
model.compile(
optimizer='adam', # 학습 속도를 조정하며 손실 함수의 최솟값을 찾습니다.
loss='binary_crossentropy', # 이진 분류에서 자주 사용되는 손실 함수
metrics=['accuracy'] # 학습 성과를 평가할 지표
)
# fit() 메서드는 모델을 학습시키는 역할
history = model.fit(
X_train, y_train, # 학습용 데이터와 레이블
validation_split=0.2, # 검증 데이터 비율 (학습 데이터의 20%)
epochs=10, # 학습 반복 횟수
batch_size=32, # 한 번의 학습에서 사용하는 데이터 샘플 수
verbose=1 # 학습 진행 상태를 출력
)
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print('테스트 손실: ', test_loss, '/ 테스트 정확도: ', test_accuracy)
# 결과: 테스트 손실: 0.4131329655647278 / 테스트 정확도: 0.8299999833106995
prediction = model.predict(X_test[:5])
print('예측결과 \n', prediction)
# 결과:
[[0.5982105 ]
[0.49192593]
[0.2119043 ]
[0.7678347 ]
[0.85198706]]결과는 확률 값이 나오는데 그 이유는 출력층 함수를 sigmoid로 사용했기 때문이다.
sigmoid는 0과 1사이로 눌러서 출력이 되므로 참고하길 바라며, 해당 문제는 이진 분류 문제이므로 출력층이 1개이다!
추가로, 일반적으로 딥러닝은 데이터 분리(필요에 따라), sequencial, complie, fit, evaluate, predict 순서를 따른다고 하니 외워두면 좋을 것 같다.
'보안 & IT 지식 🌺' 카테고리의 다른 글
| 머신러닝 & 딥러닝 (0) | 2026.01.19 |
|---|---|
| 머신러닝 & 딥러닝 (0) | 2026.01.16 |
| 머신러닝 & 딥러닝 (0) | 2026.01.14 |
| 머신러닝 & 딥러닝 (0) | 2026.01.13 |
| 머신러닝 & 딥러닝 (0) | 2026.01.12 |
